Overview
Featured projects where the Infrastructure teams have supported research at UCSF.
UCSF CoreHPC Accelerates UCSF-GPT Training from Eight-10 Months to Under 11 Hours
November 21, 2025
Bakar Computational Health Sciences Institute (BCHSI) researcher Rohit Vashisht, PhD, successfully trained UCSF-GPT–a 1.3 billion-parameter clinical foundation base model–in under 11 hours using UCSF’s CoreHPC infrastructure. The same process previously required eight-10 months–a 660-800 times improvement in training time.
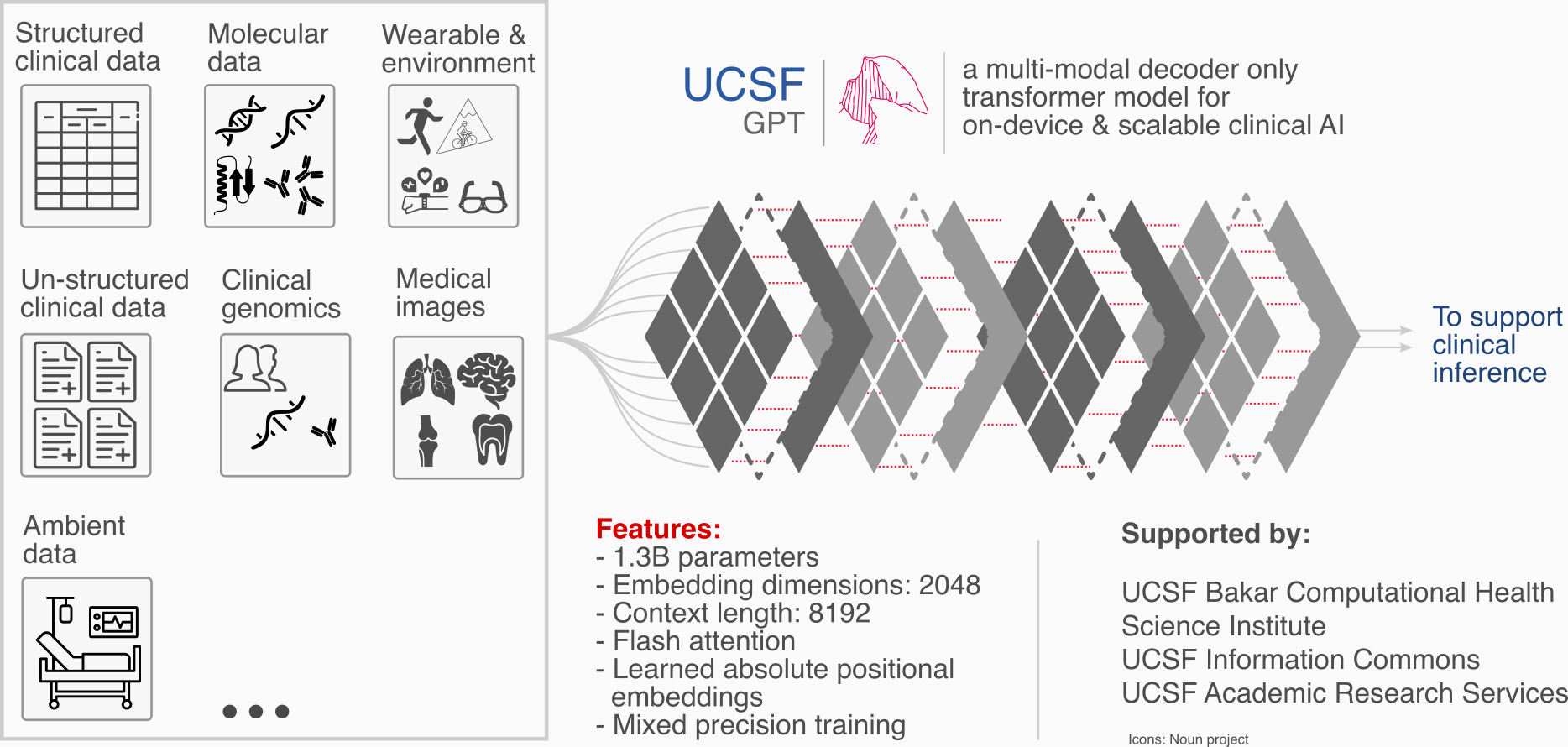
UCSF-GPT is a new multimodal AI model built at UCSF and trained entirely on de-identified medical information (clinical notes and medical research), not on internet text like ChatGPT and most other AI tools. Work is currently underway to expand UCSF-GPT beyond text to incorporate imaging, genomic, and other clinical data types. This base model will then to be fine-tuned for a wide-range of specific clinical tasks.
The Challenge
Training clinical foundation models at UCSF faced significant time constraints–Dr. Vashisht's team required eight to 10 months of continuous training on Wynton, UCSF's CPU-based computing environment with limited GPU capacity.
CPUs process data sequentially, handling tasks one at a time or across multiple cores. In contrast, CoreHPC was built as a GPU cluster designed for parallel processing, enabling it to handle massive amounts of data and perform complex calculations simultaneously. This architecture is optimized for AI model training, image analysis, and scientific simulations.
"I am genuinely in awe of the computational power now at our disposal. After nearly two years of struggling with limited compute resources, this feels nothing short of transformative–like being given the same kind of opportunity Darwin had when he was invited aboard the HMS Beagle,” said Dr. Vashisht.
The Approach
Dr. Vashisht trained the UCSF-GPT base model on CoreHPC’s multi-node H200 cluster, leveraging eight GPUs per node connected via NVLink and NCCL-based communication for gradient synchronization.
The model ingested about 68 billion tokens from UCSF’s de-identified clinical notes, radiology reports from BCHSI and ARS developed Information Commons platform, and open-access biomedical literature from PubMed.
Throughout training, the system delivered exceptional intra-node bandwidth, near-linear scaling efficiency, and stable GPU utilization across all nodes—sustaining performance levels that rival or surpass large commercial cloud infrastructures.
“The intra-node bandwidth and latency characteristics are exceptional—far superior to what I’ve observed in comparable cloud-based platforms,” said Dr. Vashisht. “It’s the kind of performance that changes how we think about large-scale model training within an academic environment.”
Results
CoreHPC completed one full UCSF-GPT training epoch—processing over 60 billion tokens— in under 11 hours. It sustained a throughput of 1.2 million tokens per second, on par with industry-standard AI platforms.
- Training time: Reduced from eight to 10 months to under 11 hours
- Throughput: 1.2 million tokens per second
- Scale efficiency: Near-linear across multi-GPU
- GPU utilization: Consistently high and stable
- Interconnect: Resilient performance over InfiniBand network in a multimode setup
Dr. Vashisht rigorously stress-tested the infrastructure across multiple dimensions, including single-epoch performance and multi-node resilience, confirming the system’s ability to maintain consistent throughput under demanding workloads.
“CoreHPC’s multi-node H200 GPU system achieved 1.2 million tokens per second throughput, enabling unprecedented speed in clinical foundation model training. It’s like reading the complete Lord of the Rings trilogy twice every second,” said Dr. Vashisht.
Impact
The significant reduction in training time marks a major leap in clinical AI research at UCSF. What once required months of continuous computation can now be achieved overnight, enabling researchers to test hypotheses, refine models, and iterate on clinical AI systems with new agility.
“Performance-wise, the improvement is transformative,” said Dr. Vashisht. “CoreHPC now truly opens the door to many experiments I wanted to conduct and have been planning for a while. This resource will have an enduring impact on our ability to push the boundaries of what is possible.”
About CoreHPC
CoreHPC, managed by UCSF Academic Research Services, is the university's high-performance computing environment designed to support large-scale data processing, AI-driven research, and compute-intensive scientific workloads.
For more information about CoreHPC, visit the CoreHPC webpage.